
Language agents: a critical evolutionary step of artificial intelligence
Language played a critical role in the evolution of biological intelligence, and now artificial intelligence seems to be following a similar evolutionary path.

What are language agents?
A heated discussion thread in AI is autonomous agents that can follow language instructions to carry out diverse and complex tasks in real-world or simulated environments. There are numerous proof-of-concept efforts on such agents recently. Just give one example to show the level of public excitement: Auto-GPT has received over 145k stars on GitHub within merely 4 months, making it the 25th most-starred repository overall and the fastest growing repository, despite its experimental nature with many known and sometimes serious limitations.
However, the concept of agent has been introduced into AI since its dawn. It’s one of the very first concepts we teach in AI 101 (e.g., from the classic textbook by Stuart Russell and Peter Norvig; Figure 1). So what's different this time around?

I argue that the most fundamental change is the capability of using language. Contemporary AI agents use language as a vehicle for both thought and communication,1 a trait that was unique to humans before these artificial agents. This dramatically expands the breadth and depth of problems these agents can possibly tackle, autonomously. Using language for communication with humans was, in my opinion, the No. 1 factor behind ChatGPT’s viral success and demonstrated that language is truly the universal interface.2 Using language for communication between agents (including humans) will lead to much more advanced multi-agent systems, a future that we are seeing some glimpses through, e.g., Park et al. (2023). There is something equally important and perhaps more unique in the current LLM-powered agents. That is, contemporary agents also use language for their thought process, which makes it much easier to incorporate heterogeneous external percepts and do multi-step (speculative) planning and reasoning, all in a non-programmed and explicit way. Therefore, to distinguish from the earlier AI agents, I’d suggest that these AI agents capable of using language for thought and communication should be called “language agents,” for language being their most salient trait.
Contemporary AI agents use language as a vehicle for both thought and communication, a trait that was unique to humans.
To see why using language is such a big deal, let’s consider an analogy in the biological intelligence (Figure 2). It is well known that many animals are intelligent: mice can learn to navigate a complex maze, pigs can learn to play a video game, and even worms exhibit long-term learning behaviors. However, all of those pale in comparison with human intelligence. While humans (and other animals) can think without language (e.g., prelinguistic infants are capable of physical reasoning), the use of language and the associated linguistic representation increase this power immensely. Using language, humans can think counterfactually and prefactually, record transient thoughts and experience for deliberation, communicate our beliefs and thought process, and accumulate and pass down knowledge for generations to come.
Artificial intelligence seems to be following a similar evolutionary path. AI agents from the previous generations, like other animals, can learn to solve a pre-defined task through repeated training, e.g., playing an Atari game. The contemporary language agents, equipped with an internalized “linguistic representation” acquired through compressing their pretraining corpus, are starting to show promising signs of broad and efficient task solving capabilities. Even though there are still numerous limitations (more on this later), I believe this is an extraordinary step in the evolution of AI, of which we are already seeing many implications. Developing and understanding such language agents is a necessary step towards more general artificial intelligence, and it might also contribute to better understanding of biological intelligence in interesting ways. For example, both the human brain and an LLM have a limited capacity that creates an information bottleneck. Both have probably been pressured to form a compact, distributed, and compositional internal representation of the world, under the pressure of survival and universally predicting the next word, respectively. Researchers have already started leveraging shallow word embeddings like word2vec as a tool to understand concept representations in the brain (Zhang et al., 2020). Understanding the more sophisticated representation in an LLM might shed further light on how an information system compactly encoding (part of) the world may emerge spontaneously.

Table of Contents
Language agents: a conceptual framework
I will discuss a potential conceptual framework for language agents (Figure 3), drawing inspirations from both classic and contemporary AI research while also making connections to related disciplines like neuroscience, cognitive science and linguistics when appropriate.
At the top level, we have the same components as in a classic AI agent—there’s an agent, optionally with embodiment, that interacts with some environment. Agents (including human agents) can cooperate or compete with each other in a multi-agent system. The true differences, however, lie within each component and how they interact with each other. I elaborate on two of them here and leave others to later:
Agent. A language agent is equipped with a memory mechanism qualitatively different from earlier agents. It includes both long-term memory and working memory. The long-term memory is mainly the pre-trained parameters of the LLM, which captures, among other things, a distributed linguistic representation acquired through compressing the pretraining data. The LLM’s context and the emergent in-context learning capability resembles human’s working memory (Baddeley, 1992) in several ways: the context serves as a scratchpad to temporarily hold task-related information, and the processing of and reasoning over the information is controlled by another attentional unit. These two forms of memory together provide an unprecedentedly powerful and versatile foundation for general-purpose language-driven reasoning.
Environment. Earlier AI agents are usually designed and programmed for a specific environment, and the environment is typically simulated or significantly simplified to fit the limits of the modeling paradigms at the time. A language agent, on the other hand, may simultaneously interact with many real-world environments of heterogeneous nature without having environment specifics hard-coded a priori. For example, to solve a complex task like “how my weekly average sleep time changes in the past 6 months,” a language agent may, in an autonomous fashion, first get the pertinent raw data from a database via SQL, calculate the weekly average by writing and executing a Python program through a code interpreter, and visualize the results through a code interpreter or Excel. What’s remarkably different is that it’s now a language agent, not a human, that bridges these heterogeneous environments: the agent can figure out how to choose and interact with the right environments, reconcile the heterogeneous formats and protocols (e.g., JSON vs. XML), and orchestrate the environmental percepts with its own reasoning steps to arrive at a coherent solution.
I should emphasize that the current language agents, despite showing promising signs, are still very unstable in such advanced capabilities. However, the mere possibility of such capabilities is already a significant advance, and I’m positive we will be able to improve their robustness over time, especially with proper collaboration with and oversight by humans.
Next I will delve deeper into several important topics related to language agents. This is not meant to be a comprehensive survey so it will miss a lot of related work. Rather, I hope to share some thoughts on where we stand on various aspects of language agents, so this discussion will be heavily opinionated. Because this is a new and fast evolving area, many of the opinions here are bound to be speculative and may turn out to be inaccurate in the future, so take it with your own discretion.
Memory
It's intriguing to examine the similarities between LLMs and human memory.
Mechanism for storage
Human memory is thought to be mainly stored in synaptic connections and new memory is formed through synaptic plasticity (Kandel, 2007), i.e., functional changes like strengthening/weakening existing synaptic connections (used for both short-term and long-term memory) or anatomical changes like removing existing connections or forming new ones (mainly used for long-term memory). An LLM's information, like other artificial neural networks, is also mainly stored in the weights (analogous to the strength of synaptic connections) of their artificial neurons, and its main mechanism of memorizing or forgetting something is through changing the weights.3 This should not be surprising because artificial neurons and neural networks were originally designed to mimic their biological counterpart. However, I find it still important to keep reminding myself of the biologically inspired root of artificial neural networks, which seems no longer at center stage in today’s discussions.
Linguistic representation
When learning language, humans form a compact, distributed, and compositional linguistic representation in memory, ranging from characters to graphemes, syllables, morphemes, words and larger structures (Dehaene, 2009). Through “compressing” the pretraining corpus, LLMs likely have formed a compact, distributed, and compositional “linguistic representation” as well, though it's not clear how similar an LLM’s is to a human’s, or whether it necessarily needs to be similar in the first place.4 I believe this internalized linguistic representation is a major factor behind LLMs' strong generalization and general reasoning capabilities.
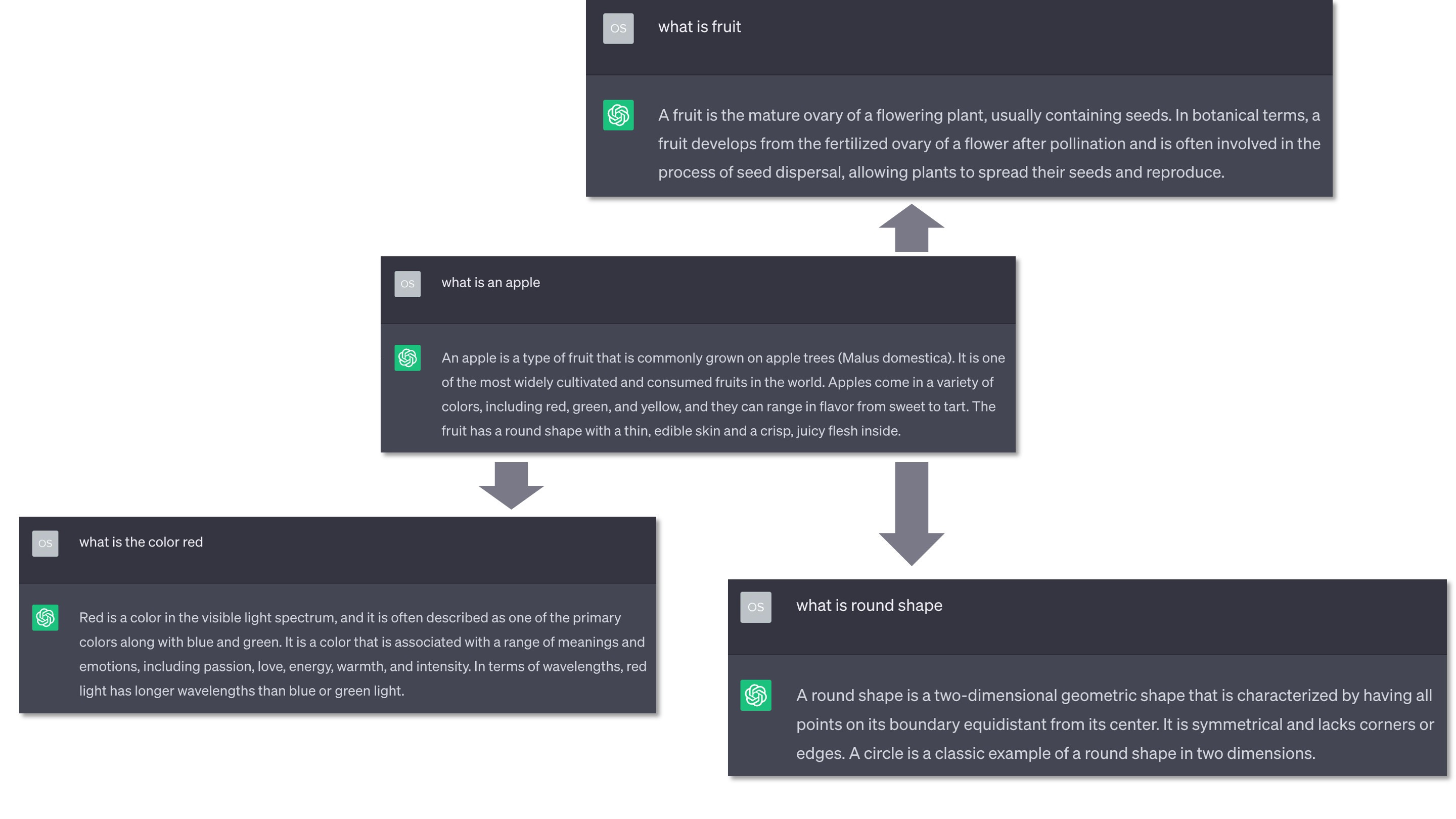
One may reasonably argue that the this representation may not be grounded in the physical world and thus there's no “true understanding.” I used to hold a similar view. But now I’m inclined to believe an alternative theory, which I call the textual twin world theory: if one has known enough about a concept, even only in pure textual forms, that could be possible to sufficiently constrain that concept in a way consistent with its definition in the physical world, thus effectively understanding the said concept. For example, as illustrated in Figure 4, an LLM may 1) “know” that an “apple” is a round-shaped fruit that typically has a red, green, or yellow skin and a crisp and juicy flesh; it belongs to the Malus genus; it is one of the most widely cultivated fruits in the world, and 2) also “know” the concepts used in that definition, e.g., “red” is a color in the visible light spectrum. All these interconnected concepts form a conceptual framework, or a textual twin, that may be largely isomorphic to that of the physical world, which may allow an LLM to unambiguously “understand” a concept without having to actually “see” the physical object and explicitly establish the grounding.5 I do still believe that having access to such grounding during learning could make learning more efficient, possibly by orders of magnitude, but that may not make it a necessary condition for learning to understand a concept.6
Long-term, short-term, and working memory
So what is the most sensible mapping from a language agent’s memory to human memory?7 Lilian Weng (2023) maps in-context learning to short-term memory and long-term memory to external vector stores. It’s a plausible mapping, but could be improved. I think working memory better characterizes in-context learning. It’s not just a scratchpad for temporarily holding information but also has a control unit to reason over the information, similar to human’s working memory. This control unit is embedded in the next-word-prediction mechanism. Interestingly, attention plays an important role in both control units.
For the long-term memory, the picture is a bit more complicated. While an external vector store does allow retrieval of (unlimited) past experiences of an agent’s, the way that currently works is qualitatively different from human’s long-term memory. Most of human’s long-term memory is structured and highly interconnected. For example, part of our long-term memory is a linguistic representation that we have learned throughout our entire life. It’s not simply a set of vectors that we retrieve from. In that sense, an LLM’s parametric memory is closer to human’s long-term memory. It captures a linguistic representation as well as a large number of facts and concepts. But we currently do not have a satisfactory way to precisely update the parametric memory and store new information (see Yao et al., 2023 for a survey on memory editing). As of now, parametric memory plus a vector database may make a reasonable system to mimic human’s long-term memory, with parametric memory holding implicit memory (e.g., some reasoning capabilities) and some semantic memory (facts and concepts), and a vector database holding some (more up-to-date) semantic memory and episodic memory (e.g., an agent’s past experiences), but significant improvements are needed for both components to approach the kind of effectiveness, efficiency, and flexibility human’s long-term memory offers.
Tool augmentation
Tool (including retrieval) augmentation is a natural extension of LLMs and language agents. Solely relying on an LLM’s static parameters can only do limited things, while tool augmentation brings unlimited possibilities. At present, tool augmentation mainly serves three purposes:
Provide up-to-date and/or domain-specific information.
Provide specialized capabilities (e.g., high-precision calculation, route planning on a map) that a language agent may not have or be best at.
Enable a language agent to take actions in real-world environments.
It’s a language agent’s capability of using language for thought and communication that makes tool augmentation possible to scale. Different tools have different input/output syntax and semantics. In the past, we would need to manually do the wiring for each tool and their interoperations. Language agents are starting to show a capability of automatically figuring out when and how to use a tool and integrating the execution results into the overall reasoning process, which is quite transformative for interoperability and versatility.
While there are earlier proof-of-concept efforts (e.g., Karpas et al., 2022, Parisi et al., 2022 and earlier retrieval-augmented LMs), ToolFormer (Schick et al., 2023) really ignited the excitement in this space, and ChatGPT Plugins relayed the excitement to the broader public. Since then, numerous work has emerged, including efforts on expanding the tool set (e.g., Liang et al., 2023, Patil et al., 2023, Qin et al., 2023), more flexible ways for learning new tools (e.g., Hao et al., 2023), and using LLMs to make new tools (e.g., Cai et al., 2023). Here is a good collection of related papers.
Generally speaking, there are two types of tools: ones that are read-only (e.g., a calculator) and ones that produce side effects in the world (e.g., APIs for sending emails or scheduling meetings). The risk associated with read-only tools are moderate—incorrect use of such tools may introduce irrelevant or incorrect information into the context, which may (or may not) affect subsequent reasoning. The ones with side effects, or state-changing tools, are much more risky and can do immediate harm. For example, you probably don’t want an agent to send a meeting invite to the CEO of your company just because it misheard your colleague’s name “Sara” as “Satya.” For this reason, most existing tool augmentation efforts limit themselves to read-only tools, or only use tools with side effects in a sandbox.
Two measures are key for successful tool augmentation: robustness and flexibility. Robustness concerns whether a language agent uses the right tool at the right time in the right way (e.g., predicting to use the right API with the right arguments), while flexibility concerns how easy it is to integrate a new tool. Robustness is also directly connected to safety, especially when using tools with side effects. As of now, while we are seeing some meaningful progress on flexibility, it’s probably fair to say that none of the existing methods/systems is sufficiently robust. How to improve robustness of tool use to production level is still largely an open question. Related to that, I believe proper human involvement is indispensable for safe use of tools with side effects. A good example is Semantic Machines et al., (2020), which was deployed as the conversational interface of Microsoft Outlook, where the user is prompted for confirmation before the agent takes any action with side effects. Still, too much dependency on the human user can quickly become a burden. This is a trade-off that hasn’t yet seen a good general solution, calling for research on better human-AI collaboration with language agents.
Grounding
Most of the truly transformative applications of language agents involve connecting an agent to some real-world environments (e.g., through tools or embodiment), be it databases (Cheng et al., 2023), knowledge graphs (Gu et al., 2023), the web (Deng et al., 2023, Zhou et al., 2023), or the physical world (Brohan et al., 2023). Each environment is a unique context that provides possibly different interpretations of natural language. Grounding, i.e., the linking of (natural language) concepts to contexts (Chandu et al., 2021), thus becomes a central and pervasive challenge.
Grounding is an overloaded term, but generally there are two types of grounding related to language agents:
Grounding natural language to an environment. For example, mapping a natural language utterance, either from human users or generated by the agent as an intermediate reasoning step, to the right plan (e.g., API call, SQL query, or a plan for an embodied agent) that, once executed, can achieve the desired effects in the corresponding environment. More formally, given an utterance u and an environment E, the goal of grounding is to produce a policy

where p is the corresponding plan for the utterance, and double square brackets denote the interpretation/denotation in the environment. This is called grounded language understanding by Gu et al., (2023) and generalizes semantic parsing.8 It is also closely related to the meaning of natural language, which, as Bender & Koller (2020) put it, is the mapping from utterance to its communicative intent. For example, when a user commands an agent to find some information in a relational database, her communicative intent can be (mostly) captured by the corresponding SQL query.
Grounding an agent’s generations and decisions in its own context (i.e., working memory), which includes external information, e.g., from tools/environments. In particular, there are a fair amount of recent work examining the attribution/verifiability aspect of LLMs (Liu et al., 2023, Yue et al., 2023, Gao et al., 2023). When an augmented LLM, e.g., a generative search engine like New Bing or Bard, lists citations to back up its generation, it’s making an attribution claim, that the generation is attributable to the referenced citations. But recent work found this attribution claim often unreliable (Liu et al., 2023); other work is trying to develop automated methods to evaluate the attribution so we can improve it accordingly (Yue et al., 2023). An LLM’s long-term parametric memory provides the predisposition for reacting to external information, but understanding how LLMs actually behave and why is still largely an open problem. One of our recent studies (Xie et al., 2023) sheds some interesting light on this: we find that LLMs can be highly receptive to external information even when that directly conflicts with their parametric memory, but only if the external information is presented in a coherent and convincing way. On the other hand, this also means that LLMs could be easily deceived by malicious tools.

Both types of grounding remain fairly challenging for language agents. Grounding will be one of the most fruitful areas for further development, from analyses and methodologies to datasets and evaluation.
Reasoning & planning
Reasoning, similar to understanding, is another controversial topic around LLMs/language agents. Generally, as probably already voiced by many others, reasoning is a continuum, not black and white. Blanket assertions like “language models cannot reason” may miss too much of the nuances. Up to this point of this long blog, it should have become evident how fond I am of thinking about the resemblances between artificial and biological intelligence. Reasoning doesn’t seem to be an untouchable trait of biological intelligence that artificial systems cannot possibly acquire. There have been many anecdotal instances of reasoning from LLMs. It may be more constructive to ask what kind of reasoning existing LLMs are good at or not so good at, and try to understand how such reasoning capabilities, or the lack thereof, originate from learning.
One interesting observation is that reasoning and planning seem to be getting blended in language agents. Traditionally, reasoning and planning, depending on how one defines these terms, are studied separately in AI. For reasoning, we think of deductive reasoning (e.g., logic-based methods) or inductive reasoning (e.g., machine learning). On the other hand, planning usually refers to a specific family of problems: given an environment, an action space, the start and goal states, find a solution as a sequence of actions. Using language as a vehicle for thought, reasoning and planning are more tightly integrated in language agents. Consider an embodied language agent acting in a partially-observable environment. It needs to continuously perceive the environment and infer the relevant environment states, based on which it plans on what to do next (Figure 5). Traditional methods usually learn a direct mapping from perception to actions, so the reasoning happens implicitly and has to be coded in the agent parameters, which creates a strong commitment to the training data and limits their generalizability. (Embodied) language agents, powered by LLMs, are starting to be able to reason explicitly with language, which greatly enhances their generalizability, explainability, and efficiency of learning.

The capability of using language as a vehicle for thought is a profound change to AI. We are already seeing new reasoning algorithms, e.g., chain-of-thought (Wei et al., 2022) and tree-of-thought (Yao et al., 2023, Long, 2023), that start to unleash some of this power. As our understanding on this progresses, I’m positive we will see more reasoning algorithms that better harness this new capability.
Embodiment, multi-agent systems, and risks
My initial intent was a short essay outlining some of my recent thinking on language agents, but this blog has gotten much longer than I’d planned, and there are still many important aspects I have not covered. Let me just share some high-level thoughts and leave the proper discussion to the future.
Embodiment is an important extension of language agents and may soon become much more important than it is now. I was impressed by how fast the robotics community seems to have embraced LLMs. SayCan (Ahn et al., 2022) is probably the most representative early work. Despite the limitations (e.g., requiring a full list of admissible actions at every step, which is a strong assumption), it showcased how LLMs can lead to more general-purpose robots. Our work of LLM-Planner (Song et al., 2023) tries to address some of these limitations through hierarchical planning and allows LLMs to focus on high-level planning. Voyager (Wang et al., 2023) and RT-2 (Brohan et al., 2023) are some of the most exciting latest developments in simulated and real-world environments, respectively. In the short term, I expect rapid progress powered by better multimodal foundation models. In the long run, I think the most exciting possibility from embodied language agents is efficient learning from first-person experience, closer to how humans learn. The pre-training of LLMs on existing text data is like learning about the world through a third-person view—the text data is artifacts produced by some cognitive processes of other (human) agents (e.g., an author writing a book to tell a story), and part of an LLM’s learning may be to infer and reconstruct that text production process.9 It may be possible to learn purely through a third-person view, but that is bound to be inefficient and data-hungry. Embodiment enables a first-person learning experience for language agents where interventions and observations of direct causal relationships become possible, which may improve the efficiency of learning by orders of magnitude.
When AI agents are equipped with the capability of using language for thought and communication, it starts to enable multi-agent systems quite different from the conventional ones (Ferber and Weiss, 1999)—agents can now act and communicate with each other in a more autonomous fashion. On the one hand, agents may now be generated with minimal specification instead of pre-programmed and can continually evolve through use and communication (e.g., Park et al., 2023). On the other hand, human users are also agents, and these artificial language agents can interact with human agents in much richer and more flexible ways than before. There are numerous emerging opportunities, such as providing guardrails and alignment for language agents and resolving uncertainties. Research on this new generation of multi-agent systems based on language agents is just starting.
The potential risks associated with language agents are very serious. They build on the immense power of LLMs and extend it further to act in the real world, autonomously. So they inherit the same risks from LLMs (e.g., bias, fairness, hallucination, privacy, and transparency), amplify some of those (e.g., workforce displacement), and also bring some of their own (e.g., taking irreversible actions). It is of utmost importance to fully understand and mitigate the potential risks. This has to be a distributed, multidisciplinary, and multidimensional endeavor by researchers, practitioners, regulators, and the public. We need to be extremely cautious and take deliberate measures before deploying language agents that can act in the real world. With that being said, I’m conservatively optimistic that we will be able to tame these seemingly wild language agents, and they may become one of the most powerful automation tools humankind has ever created.
Final remarks: is NLP dead/solved?
Many people are claiming that, with the advent of LLMs, NLP is largely solved. However, personally I think it’s the most exciting time to work on NLP ever! LLMs have indeed addressed many of the low-level language processing tasks to a large degree, but that’s more of a blessing, not a threat. Instead of focusing on natural language processing, perhaps as a field we could shift some of our focus towards natural language programming. Language agents are laying down a viable path towards turning natural language into an unprecedentedly powerful programming language that is much more expressive, flexible, and accessible than any of the formal programming languages. In the not too far future, I hope everyone can have a personal assistant (Figure 6) that automates away the tedious low-level tasks in our work and life, and allow us to reclaim our precious time for creativity and fun.

Acknowledgements
Some of the views in this article benefited from discussions with Huan Sun, Percy Liang, Luke Zettlemoyer, Jonathan Berant, Tao Yu, Shunyu Yao, Ben van Durme, Danqi Chen, Li Dong, Brian Sadler, Yu Gu, Eric Xin Wang, Yuxiao Dong, Jie Tang, Yanghua Xiao, Jacob Andreas, Jason Eisner, Wenhu Chen, and Diyi Yang. Opinions are of my own and do not represent any of these people or my affiliations.
If you find this article useful, consider citing it as follows:
@article{su2023language,
title = "Language agents: a critical evolutionary step of artificial intelligence",
author = "Su, Yu",
journal = "yusu.substack.com",
year = "2023",
month = "Sep",
url = "https://yusu.substack.com/p/language-agents"
}Mostly natural language but also programming languages.
In terms of the core capabilities, ChatGPT was probably no significantly better than its predecessors like text-devinci-003. Even OpenAI was surprised by the magnitude of ChatGPT’s popularity. Having a strong conversational capability to expose its core capabilities to general users was arguably the determining difference.
Standard learning paradigms of artificial neural networks unfortunately do not allow flexible growth of new synapses, which is key to forming long-term memory in animals. Some anatomical changes do happen, though. For example, pushing a ReLU unit into its “dead zone” effectively and permanently removes the entire neuron and all its connections from the network.
Chris Potts recently showed an interesting experiment related to this.
Text data is rooted in and derived from real-world experiences, which may produce the isomorphism in the first place.
There definitely exist certain types of human knowledge that may be impossible or extremely hard for a language agent to learn from text alone. For example, much of implicit memory, like how to ride a bike or play basketball well, is probably hard to either verbally describe or learn from only textual descriptions (multimodal models may be able to learn that). But for most of the concepts that enter our consciousness/explicit memory, it may be possible to learn from just text.
For interested readers, see Cowan (2009) for a review of the conceptual relationship and differences between long-term, short-term, and working memory, and see Kandel (2007) for the biological mechanisms behind memory.
Traditionally there are two distinct types of semantic parsing: one that concerns understanding the semantic structure of a sentence (e.g., Abstract Meaning Representation), and one that concerns mapping natural language to executable meaning representations. This often creates confusions. On the other hand, for historical reasons, the word “parsing” generally implies deriving some latent structure from a sentence, e.g., as in syntactic parsing. However, not all grounding tasks fit that framing. Sometimes the target plan in an environment could have little literal overlap with the input sentence. Take embodied or web agents as an example, for a command “get me a cup of coffee,” the target plan may be a sequence of actions like [turn left, pick up cup, move forward, …]. For these reasons, I think grounded language understanding may be a better name than semantic parsing for such tasks.
See some interesting discussion by Jacob Andreas (2022).