
Computer Use: Modern Moravec's Paradox
Why computer-use agents may be the biggest opportunity and challenge for AGI

Table of Contents
Moravec's Paradox
It was the summer of 1966, one decade after the Dartmouth conference. The nascent field of artificial intelligence had been making remarkable progress on what’s considered the crown jewel of intelligence at the time, symbolic reasoning. Newell and Simon’s Logic Theorist (1956) proved 38 of the first 52 Principia Mathematica theorems, some more elegantly than the originals. Arthur Samuel’s Checkers program (1959) learned to beat strong amateurs while demonstrating an early form of reinforcement learning. Weizenbaum’s ELIZA (1966) just gave the world a glimpse of chatbots that converse like humans.
It was amid such optimism when the Summer Vision Project was launched in Marvin Minsky’s MIT lab. A group of undergraduate students were tasked with a seemingly easy (well, at least compared with symbolic reasoning) summer project: Develop an algorithm to describe the objects in an image.1 That didn’t go as planned. The summer project turned into a multi-year grind and, eventually, ‘a small fiasco.’ Image captioning didn’t become good enough until the 2010s, five decades later.
This stark contrast in the difficulty for AI to learn symbolic reasoning versus lower-level cognitive functions like perception later became known as Moravec’s paradox: “It is comparatively easy to make computers exhibit adult level performance on intelligence tests or playing checkers, and difficult or impossible to give them the skills of a one-year-old when it comes to perception and mobility.”

In retrospect, the paradox is counterintuitive yet understandable. True symbolic thought mainly evolved in our Homo genus, at most two million years ago. By contrast, perception and mobility are highly conserved through evolution, with mechanisms dating back hundreds of millions of years; natural selection has simply had more time to optimize them. That doesn’t necessarily make these abilities more ‘intelligent’ than symbolic reasoning. However, it does allow us to evolve many sophisticated yet bespoke mechanisms (e.g., for face recognition, specialized ‘fruit detectors’, and phoneme snapping) that deeply capture how the physical world works. Perception and mobility also primarily happen subconsciously, making it harder to introspect and reverse-engineer the underlying biological mechanisms.
Moravec's Paradox in 2025
In 2025, a modern version of Moravec’s paradox is unfolding.
AI is making jaw-dropping progress on math and coding: Multiple labs have now shown gold‑medal–level performance on the 2025 International Mathematical Olympiad problems, and AI coding has become so good that vibe coding is now the talk of the town. AI seems unstoppable on such structured symbolic reasoning tasks.
With that optimism, we started to tackle a task that seems effortless to humans, using a computer to interact with the digital world, or computer-use agents (CUAs).2 In just two years, CUAs have gone from a niche academic research area3 to one of the most contested battlegrounds for AI powerhouses (OpenAI, Anthropic, Google, Microsoft, Amazon, ByteDance, Alibaba Qwen, Z.AI, among others) and a wave of new startups.
However, despite many people hailing 2025 as ‘the year of agents,’ CUAs are still far from practical use. The release of ChatGPT Agent was, all things considered, somewhat underwhelming.4 It’s slow, too costly to be economically viable, and, most importantly, unreliable. Many use cases of autonomous CUAs need very high end‑to‑end task success (often ≳95%). However, current CUAs still dwell around 30–60% on academic benchmarks (e.g., OSWorld, WebArena, Online-Mind2Web), which contain mostly simple tasks far less sophisticated than tasks many real users would want CUAs to do.
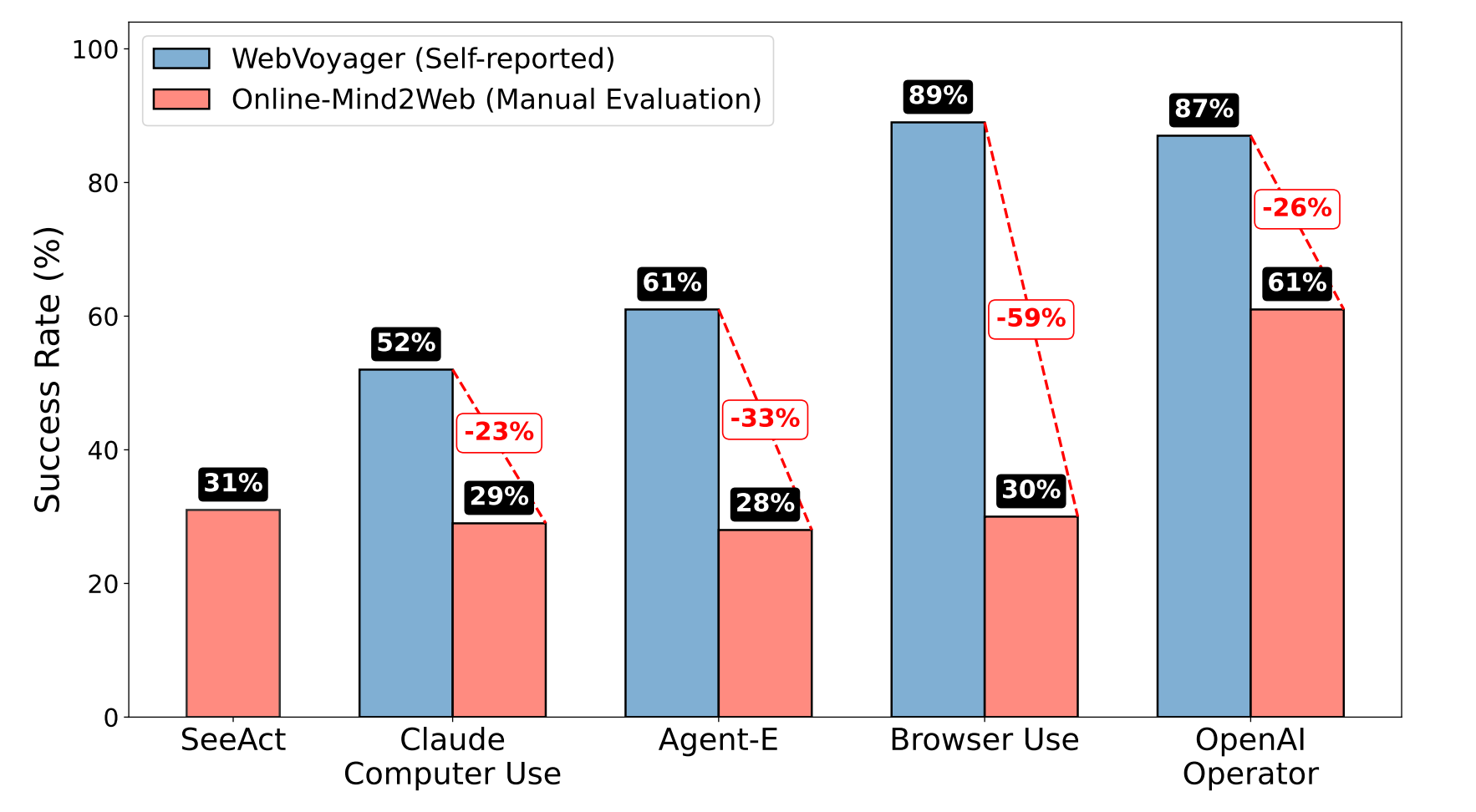
Why is computer use so hard for AI? Before answering, let’s see why it’s maybe the biggest opportunity for AGI.5
Computer use may be the biggest opportunity for AGI
It’s always about data. A consensus among researchers is that the most important ingredient for the massive success of LLMs is data, more so than any specific hardware, model architecture, or optimization algorithm. Advances in the other aspects let models efficiently ingest all the useful data on the Internet to produce intelligent behavior, but data remains the source of that intelligence.
Data is running out. It has also become clear at this point that pre-training has indeed hit a wall. The incremental improvements from GPT-4.5, GPT-5, Claude 4.1, etc. are loud evidence. We’ve nearly exhausted publicly available Internet data, but frontier LLMs are still not intelligent enough to be trusted as reliable agents beyond chatbots. Here comes the trillion-dollar question:
Where is the next Internet-scale data for AI learning?
I argue that the most promising answer lies in computer-use agents.
Chatbots → agents
Today’s models are great chatbots, better than the average human. But they are not reliable agents that can sustain goal-directed behavior across long horizons. That’s a major gap to AGI, under any plausible definition of the term. Computer use is a perfect testbed for AI agent development. The digital world is extremely broad and deep and billions of humans perform diverse, complex, goal-directed activities there every day. That creates virtually unlimited opportunities for agents to learn.
Internet-scale learning of human cognition
If one is looking for the next Internet-scale data, why look elsewhere? We may have exhausted existing Internet data, but much of it is only the artifacts of human cognition. An LLM can memorize research papers and generate plausible-looking ones, but agents are about learning the cognitive processes that produced the paper: literature review, hypothesis generation, experiment design, iteration until success, etc. In other words, Internet data are lossy compressions of cognition; it’s the polished outputs, not the messy work that produced them. We are far from exhausting what the digital world has to offer. CUAs are a natural vehicle for the next wave of Internet-scale learning that directly models human cognitive processes, not just the artifacts.
Bits > atoms
One may argue, how about robotic agents? Humanoids are all over the news! Short answer: if AGI arrives, it will likely appear in the digital world before the physical one. Compared to deploying robots in the physical world, digital agents face far fewer practical hurdles. They don’t require new hardware or sensors but run on computers we already have. This avoids all the messy physics problems like dexterous manipulation, locomotion, battery life, and wear-and-tear that have made humanoid robots slow to proliferate. We can iterate and scale software much more readily than physical machines. Achieving human-level competency on a computer is a more attainable milestone, long before we get human-level robots in the physical world.
Enormous economic value
The digital economy accounts for a large chunk of global activity, projected to reach $16.5 trillion (≈17% of global GDP) by 2028. A true ‘digital AGI worker’ would be a game changer for virtually every industry. The true value-add of CUAs isn’t replacing human workers; it’s unlocking the enormous value in the would-never-happen tasks because of their high-friction, time-consuming, and cognitively annoying nature: those small refunds and insurance appeals we never filed, unit tests never written, dead links never fixed, and experiments never run. Agents automate enough friction to lift such tasks across the threshold of worth doing. That’s new value from non-consumption to consumption, not substitution.
Why is computer use hard for AI?
So why do current AIs excel at intellectually challenging tasks like math and coding but struggle with the seemingly mundane task of computer use?
Computer use ≠ clicks + typing
Just like next-token prediction is not about capturing surface token statistics but internalizing the underlying data generation processes, computer use is much deeper than clicks and typing. What’s underneath are a myriad of (often subconscious) cognitive competencies: hierarchical planning, perceptual grounding, representation and memory, state estimation and forward modeling, pragmatics and social norms, among others. The GUI is a lossy rendering of a hidden program (e.g., a site’s local ontology, business rules, and preconditions and effect models for actions). A CUA must infer that program and operate on it, not just reacting to local changes on the GUI. Unlike next-token prediction and chatbots, CUAs must handle a dynamic stream of external observations and take state-changing actions over a long horizon—a far more error-prone yet less error-tolerant setting.

Idiosyncratic environments
Math and coding live in human-made, structured environments, i.e., formal symbolic systems. Computer use, in contrast, must deal with the messiness of the real world. Every website or app is an idiosyncratic, ever-changing ‘micro-world.’ Just like the schema names in a database are up to the individual database administrator, the semantics of GUI elements and transition dynamics are up to the individual developer and business. Here are some examples:
Naming drift (same concept, different names): GitHub Issues ≈ Jira Tickets ≈ Trello Cards ≈ Asana Tasks.
Flow variation for ‘the same’ task: for checkout, some sites require login → address → shipping → pay; others let you pay first, then create an account. Some validate postal code early, others at submit.
UI grammar differences: Pagination vs infinite scroll; inline editors vs modal forms; optimistic UI vs server-confirmed state.
From an information-theoretic perspective, it is implausible, if not impossible, for a monolithic model (as opposed to a modular system with adaptive components) to capture the infinite and ever-changing idiosyncrasies in the digital world.
Contextual understanding
Another major challenge for CUAs is their lack of personal and contextual understanding. Humans naturally draw on past actions, habits, and preferences when using computers, but AI cannot infer these unwritten details. For example, When ordering groceries, people know their brands, and when to pick generics to save money. Specifying every detail up front is tedious and defeats the point, and users often can’t specify preferences until they see intermediate results. This issue extends far beyond shopping preference to work routines, meeting schedules, how one’s files are organized, or tips picked up from casual chatting with colleagues. Humans rely on episodic memory, but current memory systems for AI are far less sophisticated.
Tacit knowledge
Humans accumulate a wealth of implicit know-how about how to accomplish goals on a computer, much of which is never formally documented. We know how to navigate common workflows and industry-specific processes simply from experience, whether it’s the typical steps to file a reimbursement in a corporate portal or the approval needed for different kinds of procurement. An extreme example of this is what I call the AWS console problem: there are hundreds of cloud services and tools on AWS that can be orchestrated into thousands of different workflows. It’s so complex that human professionals typically need months of dedicated training to earn certification. A generalist CUA is unlikely to acquire such tacit knowledge without extended continual learning on the job.
Is RL the panacea?
RL is all the rage right now. To go beyond the initial success on math and coding, new bets in frontier labs and emerging startups revolve around two complementary directions: 1) building more diverse and realistic RL gyms and 2) universal reward modeling. Optimism is so high that some see LLMs + RL gyms + reward modeling as a complete recipe for agents and even AGI. All the pieces of the puzzle have been found; it’s just a matter of further scaling each of them.
Why RL finally works beyond toy settings isn’t hard to see. Problem solving in real-world environments is a search problem with extremely large branching factors. The strong prior in LLMs (one may call it a ‘world model’) provides effective guidance for the search (just like how our strong intuition enables efficient decision making), and long chain-of-thought provides an automated and effective way to do the search (branching, backtracking, etc.). But is that enough? Is all that’s left to do just to further scale RL gyms and reward modeling with current RL algorithms and variants? It’s too early to make any assertion, but here are the questions I’ll be watching:
Can an LLM continually learn new knowledge and update outdated knowledge through RL without catastrophic forgetting or unintended ripple effects?
Can an LLM form new ‘macro-level’ abstractions (e.g., ontological understanding of a new domain or truly generalizable workflows) through RL as opposed to just reweighing and reordering existing behaviors?
Can an LLM RL-trained in sandbox environments strongly generalize to real-world environments, especially those sufficiently different from the sandboxes?
Are the current RL algorithms predominantly used for LLMs (PPO, GRPO, etc.) sufficient? Model-free RL is a preliminary form of learning that evolved in animals hundreds of millions of years ago, and humans have evolved more advanced forms of learning such as model-based RL, memory management, self-reflection, etc. Do LLMs not need any of those? Or are they already doing some of those implicitly (e.g., LLMs have certainly encoded some notion of a 'world model') and it’s just a matter of leveraging and perfecting that?
Looking forward
Computer-use agents are one of the most exciting AI frontiers, but we must keep unrealistic expectations and hype at bay. Recognizing the challenge is step one toward a solution. We are just at the start of a long journey, and there are still many fundamental gaps in research. Just as early AI researchers were startled by how thorny computer vision was, we may find ourselves in a long slog with CUAs that kind of work but fall short of true autonomy for years to come.
The good news is, computer use is such a horizontal capability that underpins virtually every modern industry. The reliability bar and marginal value vary significantly by use case. That means we can target high-friction, low-risk use cases first, where CUAs clearly outperform existing solutions and create immediate ROI, and use those early wins to bootstrap and sustain longer-term research.
At OSU NLP, with my colleague Huan Sun and amazing students, we take a uniquely holistic approach to CUA research. Here are several areas we are especially excited about, with recent papers for further reading:
Scalable (rubric-based) reward models: increasingly complex and open-ended agent tasks require more sophisticated reward models that scale. [Mind2Web 2, Online-Mind2Web]
Memory and context engineering: long-term memory concerns how to construct, organize, and recall useful information over time, while context engineering concerns what goes into the current context and in what form. [HippoRAG, HippoRAG 2]
Continual learning from experience: a necessary but notably missing capability to learn tacit knowledge and adapt to idiosyncratic environments. It intersects with memory, reward modeling, and RL. [SkillWeaver]
Agent safety and security: CUAs have a broad attack surface and are capable of causing substantial intended or unintended harm, but research on agent safety and security is far behind agent development and deployment. [EIA, RedTeamCUA, WebGuard]
Adaptive modular agent systems: we believe reliable CUAs won’t be a monolithic model but instead a modular system with adaptive modules, though the precise boundary between the foundation model and other modules will keep evolving. [UGround, WebDreamer]
References
Newell, A., Shaw, J.C. and Simon, H.A. The logic theory machine—A complex information processing system. RAND Paper P‑868, 1956.
Samuel, A.L. Some studies in machine learning using the game of checkers. IBM Journal of Research and Development 3(3):210–229, 1959.
Weizenbaum, J. Eliza—A computer program for the study of natural language communication between man and machine. Communications of the ACM 9(1):36–45, 1966.
Papert, S.A. The summer vision project. MIT AI Memo 100, 1966.
Moravec, H. Mind children: The future of robot and human intelligence. Harvard University Press, 1988.
Deng, X., Gu, Y., Zheng, B., Chen, S., Stevens, S., Wang, B., Sun, H. and Su, Y. Mind2Web: towards a generalist agent for the web. NeurIPS 2023 (Datasets & Benchmarks).
Zhou, S., Xu, F.F., Zhu, H., Zhou, X., Lo, R., Sridhar, A., Cheng, X., Ou, T., Bisk, Y., Fried, D., Alon, U. and Neubig, G. WebArena: a realistic web environment for building autonomous agents. ICLR 2024.
Zheng, B., Gou, B., Kil, J., Sun, H. and Su, Y. GPT‑4V(ision) is a generalist web agent, if grounded. ICML 2024.
Xie, T., Zhang, D., Chen, J., Li, X., Zhao, S., Cao, R., Toh, J.H., Cheng, Z., Shin, D., Lei, F., Liu, Y., Xu, Y., Zhou, S., Savarese, S., Xiong, C., Zhong, V. and Yu, T. OSWorld: benchmarking multimodal agents for open‑ended tasks in real computer environments. NeurIPS 2024 (Datasets & Benchmarks).
Yao, S., Chen, H., Yang, J. and Narasimhan, K. WebShop: towards scalable real‑world web interaction with grounded language agents. NeurIPS 2022.
Shi, T., Karpathy, A., Fan, L., Hernandez, J. and Liang, P. World of Bits: an open‑domain platform for web‑based agents. ICML 2017.
Nakano, R. et al. WebGPT: using web browsing to answer open‑ended questions. OpenAI research blog, 2021.
He, H., Yao, W., Ma, K., Yu, W., Dai, Y., Zhang, H., Lan, Z. and Yu, D. WebVoyager: building an end‑to‑end web agent with large multimodal models. ACL 2024.
HAL (Holistic Agent Leaderboard). Open benchmarking harness & leaderboard for agents. https://hal.cs.princeton.edu.
OpenAI. Introducing ChatGPT agent: bridging research and action. OpenAI blog, 2025.
Xue, T., Qi, W., Shi, T., Song, C.H., Gou, B., Song, D., Sun, H. and Su, Y. An illusion of progress? assessing the current state of web agents. COLM 2025.
Gou, B., Huang, Z., Ning, Y., Gu, Y., Lin, M., Qi, W., Kopanev, A., Yu, B., Jiménez Gutiérrez, B., Shu, Y., Song, C.H., Wu, J., Chen, S., Moussa, H.N., Zhang, T., Xie, J., Li, Y., Xue, T., Liao, Z., Zhang, K., Zheng, B., Cai, Z., Rozgic, V., Ziyadi, M., Sun, H. and Su, Y. Mind2Web 2: evaluating agentic search with agent‑as‑a‑judge. arXiv:2506.21506, 2025.
Jiménez Gutiérrez, B., Shu, Y., Gu, Y., Yasunaga, M. and Su, Y. HippoRAG: neurobiologically inspired long‑term memory for large language models. NeurIPS 2024.
Jiménez Gutiérrez, B., Shu, Y., Qi, W., Zhou, S. and Su, Y. From RAG to memory: non‑parametric continual learning for large language models. ICML 2025.
Zheng, B., Fatemi, M.Y., Jin, X., Wang, Z.Z., Gandhi, A., Song, Y., Gu, Y., Srinivasa, J., Liu, G., Neubig, G. and Su, Y. SkillWeaver: web agents can self‑improve by discovering and honing skills. arXiv:2504.07079, 2025.
Liao, Z., Mo, L., Xu, C., Kang, M., Zhang, J., Xiao, C., Tian, Y., Li, B. and Sun, H. EIA: environmental injection attack on generalist web agents for privacy leakage. ICLR 2025.
Liao, Z., Jones, J., Jiang, L., Fosler‑Lussier, E., Su, Y., Lin, Z. and Sun, H. RedTeamCUA: realistic adversarial testing of computer‑use agents in hybrid web‑OS environments. arXiv:2505.21936, 2025.
Zheng, B., Liao, Z., Salisbury, S., Liu, Z., Lin, M., Zheng, Q., Wang, Z., Deng, X., Song, D., Sun, H. and Su, Y. WebGuard: building a generalizable guardrail for web agents. arXiv:2507.14293, 2025.
Gou, B., Wang, R., Zheng, B., Xie, Y., Chang, C., Shu, Y., Sun, H. and Su, Y. Navigating the digital world as humans do: universal visual grounding for GUI agents. ICLR 2025.
Gu, Y., Zhang, K., Ning, Y., Zheng, B., Gou, B., Xue, T., Chang, C., Srivastava, S., Xie, Y., Qi, P., Sun, H. and Su, Y. Is your LLM secretly a world model of the internet? model‑based planning for web agents. arXiv:2411.06559, 2024.
This is the origin of the famous myth of Minsky claiming ‘undergrads will solve vision in a summer.’ Minsky probably didn’t use that literal phrasing, but the myth might be directionally true given his typically exuberant timetable on AI progress and reflect the over-optimism at the time.
By ‘computer-use agent’ (CUA) we mean any AI system that perceives, reasons, and acts within digital environments to achieve user goals using the same affordances available to people, across web, desktop, and mobile, via GUIs and non-GUI channels (APIs, CLIs, file systems, protocols). CUAs are interface-agnostic and goal-directed: they can click/type, call services, move data across apps, and orchestrate end-to-end workflows. This definition is deliberately broad, subsuming chat+tools, API automation, and GUI agents, because the core idea is competent action in the digital world, not a particular interaction style.
Early LLM-based CUAs: Mind2Web (NeurIPS’23), WebArena (ICLR’24), SeeAct (ICML’24) OSWorld (NeurIPS’24). WebShop (NeurIPS’22) is another good early attempt, though not LLM-based. Other salient early attempts include MiniWoB (ICML’17; toy web environments for RL) and WebGPT (browsing for question answering).
In all fairness, I think there are solid technical improvements under the hood, but the over-hyping prior to the launch backfires.
I don’t personally endorse the term ‘AGI.’ It’s ambiguous and can bring artificial negative connotation of competing with or replacing humans. But one goal of this post is to point out that the challenge to achieve the next stage of AI is more steep than the current optimism, we might as well use AGI to refer to the highest AI ambition people currently have, no matter the definition.
Some aspects like security considerations and data privacy further make these harder in real world deployments